Train and restore with trivial conv net#
This example attempts to train a trivial convolutional neural network to restore a blurred and noisy image.
The example is not expected to produce good results as currently written as the receptive field of the network is small (there are not pooling layers). The main purpose of the example is simply to show that a ‘shallow’ network cannot procuce good results.
In the future the example may be improved to demonstrate how adding pooling layers (or other strategies) to increase the receptive field improves the performance.
import tensorflow as tf
import numpy as np
import os
from skimage.io import imread
Get list of devices#
In this step you want to confirm there is a GPU available
# Get the list of visible devices
visible_devices = tf.config.list_physical_devices()
print(visible_devices)
#from tensorflow.python.client import device_lib
#print(device_lib.list_local_devices())
[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
Set network architecture#
In this case the network is 3, 3D conv-nets but no pooling. We don’t expect this type of network to perform too well.
# Set random seed for reproducibility
tf.random.set_seed(52)
# Define the CNN architecture
def create_model(input_shape):
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv3D(4, (7, 7, 7), padding='same', activation='relu', input_shape=input_shape))
model.add(tf.keras.layers.Conv3D(4, (7, 7, 7), padding='same', activation='relu'))
model.add(tf.keras.layers.Conv3D(1, (7, 7, 7), padding='same'))
return model
# Define the loss function
def mse_loss(y_true, y_pred):
return tf.reduce_mean(tf.square(y_true - y_pred))
# Define the optimizer
optimizer = tf.keras.optimizers.Adam(lr=1e-3)
c:\Users\bnort\miniconda3\envs\decon-dl-env\lib\site-packages\keras\optimizers\optimizer_v2\adam.py:114: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
super().__init__(name, **kwargs)
Load the corrupted images and ground truth images#
… add a trivial channel, normalize the intensities and form an array of training images
import os
data_dir = r'../../data/deep learning training/'
corrupted_dir = os.path.join(data_dir,'spheres_big_small_noise_high_na_high/train/input0')
ground_truth_dir = os.path.join(data_dir,'spheres_big_small_noise_high_na_high/train/ground truth0')
corrupted_files = os.listdir(corrupted_dir)
ground_truth_files = os.listdir(ground_truth_dir)
# Preprocess the images
X_train = []
Y_train = []
for i in range(len(corrupted_files)):
# Load the corrupted image and ground truth image
corrupted_img = imread(os.path.join(corrupted_dir, corrupted_files[i]), plugin='tifffile')
ground_truth_img = imread(os.path.join(ground_truth_dir, ground_truth_files[i]), plugin='tifffile')
# Resize the images to the desired size
#corrupted_img = np.reshape(corrupted_img, (256, 256, 100, 1))
#ground_truth_img = np.reshape(ground_truth_img, (256, 256, 100, 1))
# add trivial channels dimension
corrupted_img = corrupted_img[..., np.newaxis]
ground_truth_img = ground_truth_img[..., np.newaxis]
print(corrupted_img.min(), corrupted_img.max())
print(ground_truth_img.min(), ground_truth_img.max())
# Normalize the pixel values to [0, 1]
corrupted_img = (corrupted_img.astype('float32')-corrupted_img.min()) / (corrupted_img.max() - corrupted_img.min())
ground_truth_img = (ground_truth_img.astype('float32')-ground_truth_img.min()) / (ground_truth_img.max() - ground_truth_img.min())
# Append the preprocessed images to the training set
X_train.append(corrupted_img)
Y_train.append(ground_truth_img)
X_train = np.array(X_train)
Y_train = np.array(Y_train)
5 198
0.0 281.5
2 74
0.0 161.0
2 142
0.0 366.0
3 141
0.0 287.5
4 198
0.0 395.0
3 160
0.0 394.0
5 257
0.0 354.5
2 214
0.0 364.0
1 126
0.0 343.0
1 138
0.0 352.0
0 95
0.0 281.0
5 247
0.0 342.5
2 136
0.0 357.5
2 96
0.0 378.0
1 89
0.0 354.0
2 157
0.0 391.5
5 214
0.0 392.5
2 154
0.0 364.5
4 214
0.0 394.5
3 197
0.0 396.0
3 233
0.0 365.5
2 227
0.0 308.5
2 152
0.0 375.0
1 144
0.0 362.0
4 291
0.0 399.0
print(X_train.shape)
(25, 32, 128, 128, 1)
Define and compile a model, perform training and save#
# Define the input shape of the model
input_shape = X_train[0].shape
# Create the model
model = create_model(input_shape)
# Compile the model
model.compile(loss=mse_loss, optimizer=optimizer)
# Train the model
model.fit(X_train, Y_train, batch_size=16, epochs=5, validation_split=0.2)
# Save the model
model.save('restoration_model.h5')
Epoch 1/5
2/2 [==============================] - 9s 2s/step - loss: 0.1246 - val_loss: 0.0814
Epoch 2/5
2/2 [==============================] - 2s 437ms/step - loss: 0.0793 - val_loss: 0.0946
Epoch 3/5
2/2 [==============================] - 2s 445ms/step - loss: 0.0787 - val_loss: 0.0704
Epoch 4/5
2/2 [==============================] - 2s 452ms/step - loss: 0.0684 - val_loss: 0.0832
Epoch 5/5
2/2 [==============================] - 2s 468ms/step - loss: 0.0669 - val_loss: 0.0788
Try with more epochs#
model.fit(X_train, Y_train, batch_size=16, epochs=15, steps_per_epoch=200, validation_split=0.2)
Epoch 1/15
30/200 [===>..........................] - ETA: 2:04 - loss: 0.0569WARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least `steps_per_epoch * epochs` batches (in this case, 3000 batches). You may need to use the repeat() function when building your dataset.
200/200 [==============================] - 24s 111ms/step - loss: 0.0569 - val_loss: 0.0569
<keras.callbacks.History at 0x1401b39c190>
Generate example result#
from tnia.plotting.projections import show_xy_zy_max
n=0
print(X_train[n].shape, X_train[n].min(), X_train[n].max())
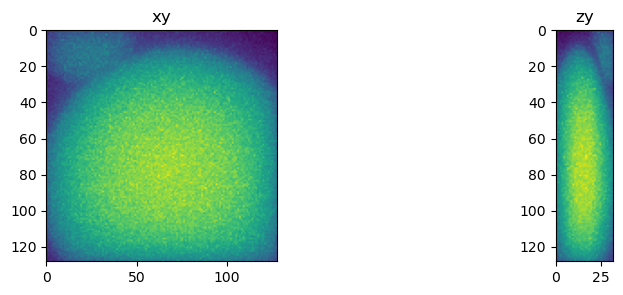
fig = show_xy_zy_max(np.squeeze(X_train[[n]]))
print(Y_train[n].shape, Y_train[n].min(), Y_train[n].max())
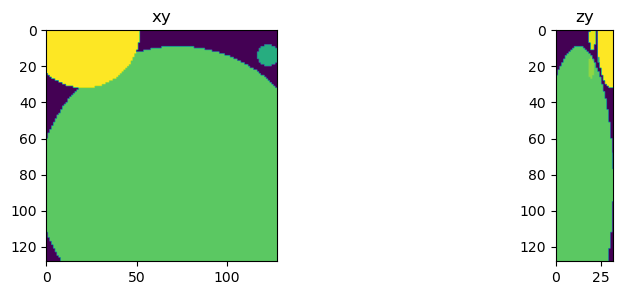
fig = show_xy_zy_max(np.squeeze(Y_train[n]))
(32, 128, 128, 1) 0.0 1.0
(32, 128, 128, 1) 0.0 1.0
X_train[n].shape
(32, 128, 128, 1)
n=10
#output = model.predict(X_train[0])
input = X_train[n].reshape(1, 32, 128, 128, 1)
truth = Y_train[n].reshape(1, 32, 128, 128, 1)
output = model.predict(input)
print(output.shape)
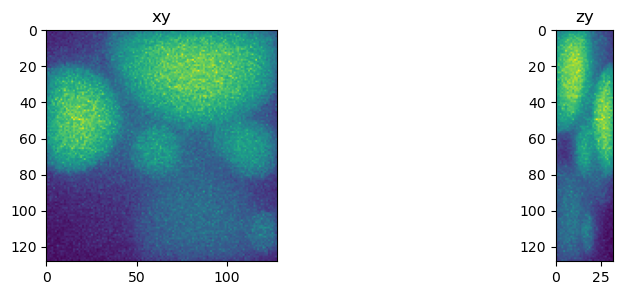
fig = show_xy_zy_max(np.squeeze(input))
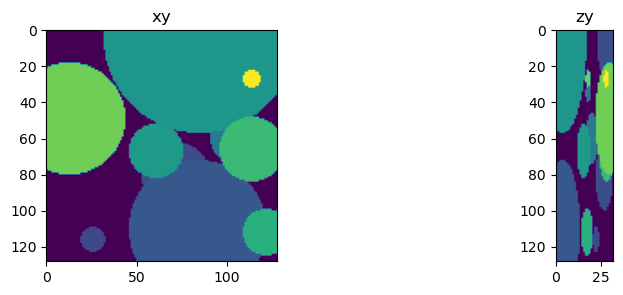
fig = show_xy_zy_max(np.squeeze(truth))
fig = show_xy_zy_max(np.squeeze(output))
1/1 [==============================] - 0s 26ms/step
(1, 32, 128, 128, 1)
test=np.squeeze(output)
print(Y_train[n].shape, Y_train[n].min(), Y_train[n].max())
print(test.min(), test.max())
#test=test-test.min()
fig = show_xy_zy_max(Y_train[n])
fig = show_xy_zy_max(X_train[n])
fig = show_xy_zy_max(test)
(32, 128, 128, 1) 0.0 1.0
-0.068902574 1.647787
test.min(), test.max()
(0.0, 0.39403412)
import napari
viewer = napari.Viewer()
viewer.add_image(np.squeeze(X_train[1]), name='corrupted')
viewer.add_image(np.squeeze(Y_train[1]), name='ground truth')
viewer.add_image(test, name='restored')
<Image layer 'restored' at 0x2af2f988f70>
X_train[0].shape
(86, 256, 256, 1)
test.shape
(1, 86, 256, 256, 3)
Y_train[0].shape
(86, 256, 256, 1)