Train a cellpose 2D model for different scales#
Before running this notebook a set of patches must exist in the following format.
Ground Truth are put in a directory called
/ground truth0Inputs are put in a directory called
inputnwhere n is an integer 0…m and represents the channel. Note: RGB images may only have one ‘channel’ directory.In each of the both directories there exist a set of files of the same names. For example if in the
inputndirectory we haveapples0,apples1,apples2label images of the same name must exist in theground truthdirectory.
import os
from tnia.plotting.plt_helper import imshow_multi2d
from cellpose import models, io
from pathlib import Path
Load inputs and ground truth#
We load directories called ‘input0’ and ‘ground truth0’ which should exist under train_path. The reason we append ‘0’ to the end of the name is because some of the code that generates image and label sets is meant to work on multiple channels (so the 0 is the channel number)
data_path = r'../../data'
parent_path = os.path.join(data_path, 'ladybugs_series')
train_path = os.path.join(parent_path, 'patches')
image_patch_path = train_path + '/ground truth0'
label_patch_path = train_path + '/input0'
model_path = os.path.join(parent_path,'models')
if not os.path.exists(model_path):
os.makedirs(model_path)
if not os.path.exists(image_patch_path):
print('image_patch_path does not exist')
if not os.path.exists(label_patch_path):
print('label_patch_path does not exist')
Use a helper to collect the training data#
The helper will also normalize the inputs.
from tnia.deeplearning.dl_helper import collect_training_data
X, Y = collect_training_data(train_path, sub_sample=1, downsample=False, add_trivial_channel=False, relabel=True)
print('Number of input images', len(X))
print('Number of ground truth images ', len(Y))
print('Size of first input image', X[0].shape)
print('Size of first ground truth image ', Y[0].shape)
Number of input images 552
Number of ground truth images 552
Size of first input image (512, 512, 3)
Size of first ground truth image (512, 512)
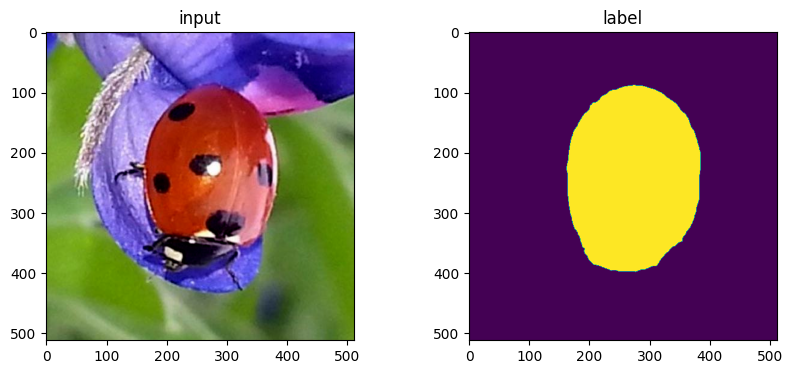
Inspect images#
Output training data shapes and plot images to make sure image and label set look OK
print(X[0].shape, Y[0].shape)
print(X[0].min(), X[0].max())
fig=imshow_multi2d([X[2], Y[2]], ['input', 'label'], 1,2)
(512, 512, 3) (512, 512)
0.0 1.0
Divide into training and validation sets#
Unlike stardist Cellpose does not seem to need numpy arrays as input. So to create training and validation sets we can simply split the X and Y vectors.
X_ = X.copy()
Y_ = Y.copy()
# note we don't have a lot of training patches so we will use them for both training and testing (very bad but this is just for proof of concept)
X_train = X_
Y_train = Y_
X_test = X_.copy()
Y_test = Y_.copy()
print('Number of images', len(X_))
print('Number of training images', len(X_train))
print('Number of test images ', len(X_test))
Number of images 552
Number of training images 552
Number of test images 552
X_train[0].shape, Y_train[0].shape
((512, 512, 3), (512, 512))
Create a cellpose model#
import os
model_name = 'cellpose_ladybugs_scale2'
# start logger (to see training across epochs)
logger = io.logger_setup()
# DEFINE CELLPOSE MODEL (without size model)
model= models.CellposeModel(gpu=True, model_type=None)#, pretrained_model=os.path.join(model_path,model_name))
creating new log file
2024-10-24 12:24:30,503 [INFO] WRITING LOG OUTPUT TO C:\Users\bnort\.cellpose\run.log
2024-10-24 12:24:30,504 [INFO]
cellpose version: 3.0.9
platform: win32
python version: 3.10.14
torch version: 2.2.2+cu118
2024-10-24 12:24:30,506 [INFO] ** TORCH CUDA version installed and working. **
2024-10-24 12:24:30,506 [INFO] >>>> using GPU
2024-10-24 12:24:30,650 [INFO] >>>> no model weights loaded
Train the model#
from cellpose import train
channel_to_segment = 2
optional_channel = 3
new_model_path = train.train_seg(model.net, X_train, Y_train,
#test_data=X_val,
#test_labels=Y_val,
channels=[0,1],
save_path=parent_path,
n_epochs=50,
min_train_masks=0,
#learning_rate=learning_rate,
#weight_decay=weight_decay,
rescale = False,
bsize = 512,
#nimg_per_epoch=400,
model_name=model_name,
normalize=False)
2024-10-24 12:24:31,958 [INFO] computing flows for labels
100%|██████████| 552/552 [01:19<00:00, 6.97it/s]
2024-10-24 12:25:51,686 [INFO] >>> computing diameters
100%|██████████| 552/552 [00:00<00:00, 783.96it/s]
2024-10-24 12:25:52,395 [INFO] >>> using channels [0, 1]
2024-10-24 12:25:55,272 [INFO] >>> n_epochs=50, n_train=552, n_test=None
2024-10-24 12:25:55,273 [INFO] >>> AdamW, learning_rate=0.00500, weight_decay=0.00001
c:\Users\bnort\miniconda3\envs\pytorch_and_SAM3\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
2024-10-24 12:25:56,974 [INFO] >>> saving model to C:\Users\bnort\work\ImageJ2022\tnia\notebooks-and-napari-widgets-for-dl\data\ladybugs_series\models\cellpose_ladybugs_scale2
2024-10-24 12:26:36,421 [INFO] 0, train_loss=2.3403, test_loss=0.0000, LR=0.0000, time 39.45s
2024-10-24 12:30:01,591 [INFO] 5, train_loss=1.3892, test_loss=0.0000, LR=0.0028, time 244.62s
2024-10-24 12:33:29,520 [INFO] 10, train_loss=0.6775, test_loss=0.0000, LR=0.0050, time 452.55s
2024-10-24 12:40:23,661 [INFO] 20, train_loss=0.3807, test_loss=0.0000, LR=0.0050, time 866.69s
2024-10-24 12:47:18,147 [INFO] 30, train_loss=0.2567, test_loss=0.0000, LR=0.0050, time 1281.17s
2024-10-24 12:54:12,491 [INFO] 40, train_loss=0.1621, test_loss=0.0000, LR=0.0050, time 1695.52s
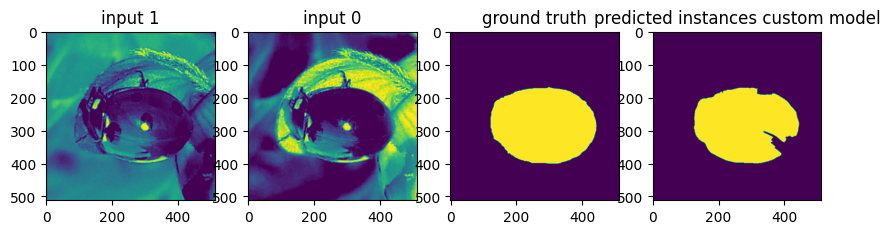
Test network on one of the training images (self prediction)#
Self prediction is not a good way to evaluate the ‘real’ performance of the NN. However it is good sanity test. If the self prediction looks wrong something really went bad.
# run model on test images
n=12
masks = model.eval(X_train[n], channels=[0, 1], normalize=False)
fig = imshow_multi2d([X_train[n][:,:,channel_to_segment-1], X_train[n][:,:,optional_channel-1], Y_train[n], masks[0]],['input 1','input 0', 'ground truth','predicted instances custom model'],1,4)